sed 和 awk 以及 cut 算是常用工具了,sed的高级用法也需要知道一下
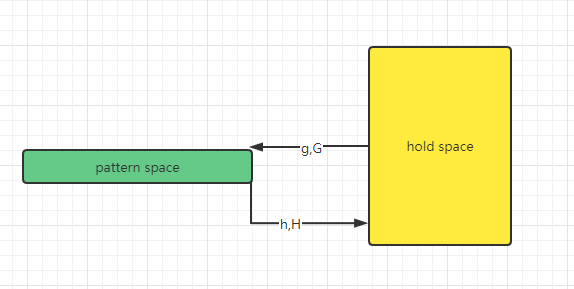
sed 里面有2个空间,一个是pattern space,一个是hold space,默认都是空的
开始处理的时候,就从文件里一行一行读入 pattern space ,进行处理,hold space 只在你需要用到它的时候才会出现:
d : 清空pattern space中的内容,立即开始下个循环(意思是跳过默认的输出pattern space内容的阶段???不知理解的对不对)
h : 用pattern space中的内容替换hold pattern中的内容
H : 在hold space中的内容后面追加一个换行,把pattern space中的内容追加到hold space中
g : 用hold space中的内容替换pattern space中的内容
G : 在pattern space中的内容后面追加一个换行,把hold space中的内容追加到pattern space中
h, g会替换(可以理解为先清空,再复制), H, G是追加。
hH是放过去,gG是拿过来,小写是替换,大写是追加
分析一下经典的将文件内容反向打印
cat 1.txt
1
2
3
cat 1.txt | sed -n '1!G;h;$p'
3
2
1
‘1!G;h;$p’ 分析一下,1!G就是说第一行不执行G,从第二行开始执行G;然后h是每行都执行,最后一行的时候执行p
input | pattern | hold | command | pattern | hold | command | pattern | hold
1 | 1 | 空行 | | 1 | 空行 | h | 1 | 1
2 | 2 | 1 | G | 21 | 1 | h | 21 | 21
3 | 3 | 21 | G | 321 | 21 | h | 321 | 321
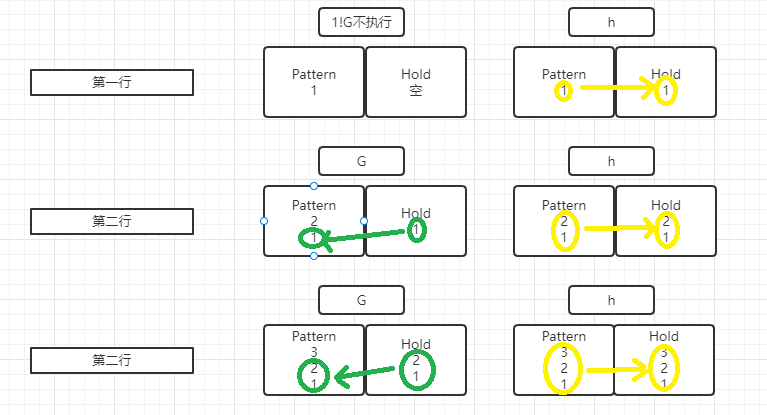
因为之前的参数是 -n 不打印,直到最后一行,$p打印Pattern空间里的内容,这样就直接被反转打印出来了。
。