普遍的大数据抽数的方式都是从散落在各个地方的 MySQL 数据库中开账号,然后把数据同步过来。
这不,大数据的同事提出了一个需求,想把某个库中的某个表的数据单独同步到大数据的统一库中的某个表中。
研究了一个星期,canal 的配置对运维来说非常的不友好,除非用它那个 admin 的 dashboard,但是运维通常是 cli 界面,谁没事装个 dashboard 来配置呢,太 low 了。
用的是 canal 1.1.5 的版本,不能升级,升级后 java 不对了。还没有到用 1.1.6 的时候!
背景:
源数据库:10.8.2.12
库:xxl_job
表:demotable666
目的数据库:10.8.2.17
库:xxl_job_bak
表:demotable666
而且不用任何的Zookeeper、Kafka、RabbitMQ的中间件,越简洁越好。
一、安装canal
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.deployer-1.1.5.tar.gz
wget https://github.com/alibaba/canal/releases/download/canal-1.1.5/canal.adapter-1.1.5.tar.gz
#都装到 /app 目录下
mkdir /app
mkdir /app/deploy
mkdir /app/adapter
cd /app/deploy
tar zxvf canal.deployer-1.1.5.tar.gz
cd /app/adapter
tar zxvf canal.adapter-1.1.5.tar.gz
二、MySQL源准备
# /etc/my.cnf 加入以下几项并重启
[mysqld]
log-bin=mysql-bin # Start log bin.
binlog_format=ROW # Log format.
server-id=1 # Server id,different from slave.
授权binlog同步:
# 创建用户授权
mysql> CREATE USER canal IDENTIFIED BY 'canal';
mysql> GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'10.8.2.17' identified by "xxxxxx";
mysql> FLUSH PRIVILEGES;
# 查看授权
mysql> show grants for 'canal';
三、配置deploy
其实关键就是两个配置
1、canal.properties
mkdir /app/deploy/conf/10.8.2.12
cp /app/deploy/conf/example/instance.properties /app/deploy/conf/10.8.2.12
vi /app/deploy/conf/canal.properties
#就改两个地方
canal.destinations = 10.8.2.12
canal.auto.scan = false
注意,上面一定要把 canal.auto.scan 修改成 false,否则它会自动扫描 conf 目录下的所有配置,这样 example 子目录无论是否有用到,配置都会被扫进去。这不是神经病么,典型的 java 程序猿自以为是的配置。
2、instance.properties 的配置
vi /app/deploy/conf/10.8.2.12/instance.properties
# instance.properties 是拷贝example目录中的
# 改动
canal.instance.master.address=10.8.2.12:3306
canal.instance.tsdb.enable=false
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=xxxxxx
# table regex
#1. 所有表:.* or .*\\..*
#2. canal schema下所有表: canal\\..*
#3. canal下的以canal打头的表:canal\\.canal.*
#4. canal schema下的一张表:canal\\.test1
#5. 多个规则组合使用:canal\\..*,mysql.test1,mysql.test2 (逗号分隔)
#canal.instance.filter.regex=.*\\..*
canal.instance.filter.regex=xxl_job\\..*
上面其实就是设置了 canal 去伪装成一个 slave,读取 binlog 日志,并且过滤只读取 xxl_job 的日志。
启动 deploy
cd /app/deploy/bin
./startup.sh
看看日志无异常即可:
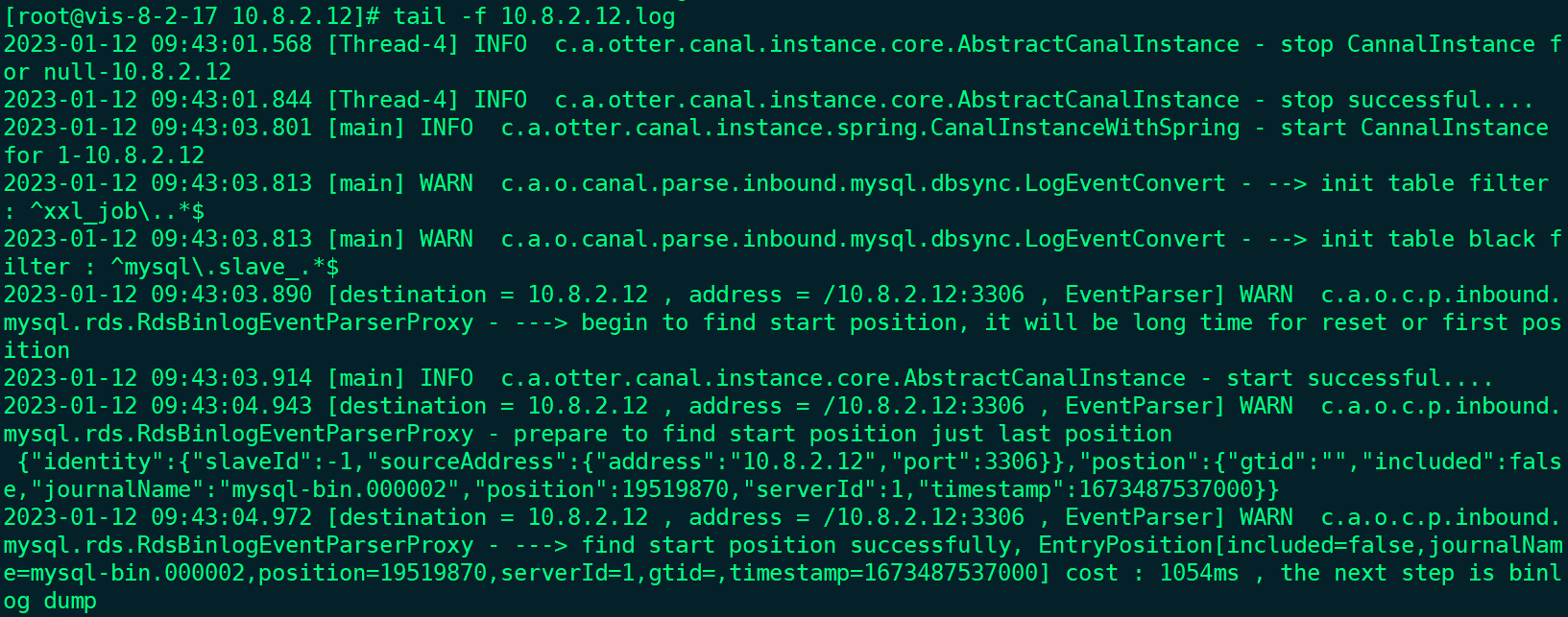
四、准备好目的数据库的库表结构
源数据库已经有 demotable666 的表了,我们需要在目的数据库事先准备好 demotable666
# 在 10.8.2.17 的 xxl_job_bak 库上执行
mysql> use xxl_job_bak;
mysql> create table demotable666(
UserId int NOT NULL AUTO_INCREMENT PRIMARY KEY,
UserName varchar(100),
UserLoginDate date NOT NULL
);
Query OK, 0 rows affected (0.04 sec)
五、设置adapter
1、application.yml
首先给 canal 的机器对目的库赋 mysql 权
mysql> grant all privileges on xxl_job_bak.* to sync_17@'%' identified by "xxxxxx";
mysql> flush privileges;
然后编辑application.yml
vi /app/adapter/conf/application.yml
#注释掉srcDataSources,mysql 同步到 mysql的场景中完全用不到这个,es要用到
# srcDataSources:
# defaultDS:
# url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true
# username: root
# password: 121212
canalAdapters:
- instance: 10.8.2.12 # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: rdb
key: mysqlbak1
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://10.8.2.17:3306/xxl_job_bak?useUnicode=true
jdbc.username: sync_17
jdbc.password: xxxxxx
注意上面配的instance,这个跟deploy里面的instance没有半毛钱关系,这个是为了rdb里面的配置参考用的。
2、编辑表同步配置文件mysqlbak1.yml
注意上面的jdbc.url指定了库是xxl_job_bak,所以下面配置的 targetTable 就是单独一个 demotable666,很多文章里写库名.表名, xxl_job_bak.demotable666,八戒是没这样成功。
#用不到的挪成备份
mv /app/adapter/conf/rdb/mytest_user.yml /app/adapter/conf/rdb/mytest_user.bak
vi /app/adapter/conf/rdb/mysqlbak1.yml
#dataSourceKey: mysqlbakDS1
# cannal的instance或者MQ的topic
destination: 10.8.2.12
groupId: g1
outerAdapterKey: mysqlbak1
concurrent: true
dbMapping:
database: xxl_job
table: demotable666
targetTable: demotable666
targetPk:
UserId: UserId
# mapAll: true
targetColumns:
UserId:
UserName:
UserLoginDate:
# etlCondition: "where c_time>={}"
commitBatch: 1 # 批量提交的大小
启动 adapter:
cd /app/adapter/bin
./startup.sh
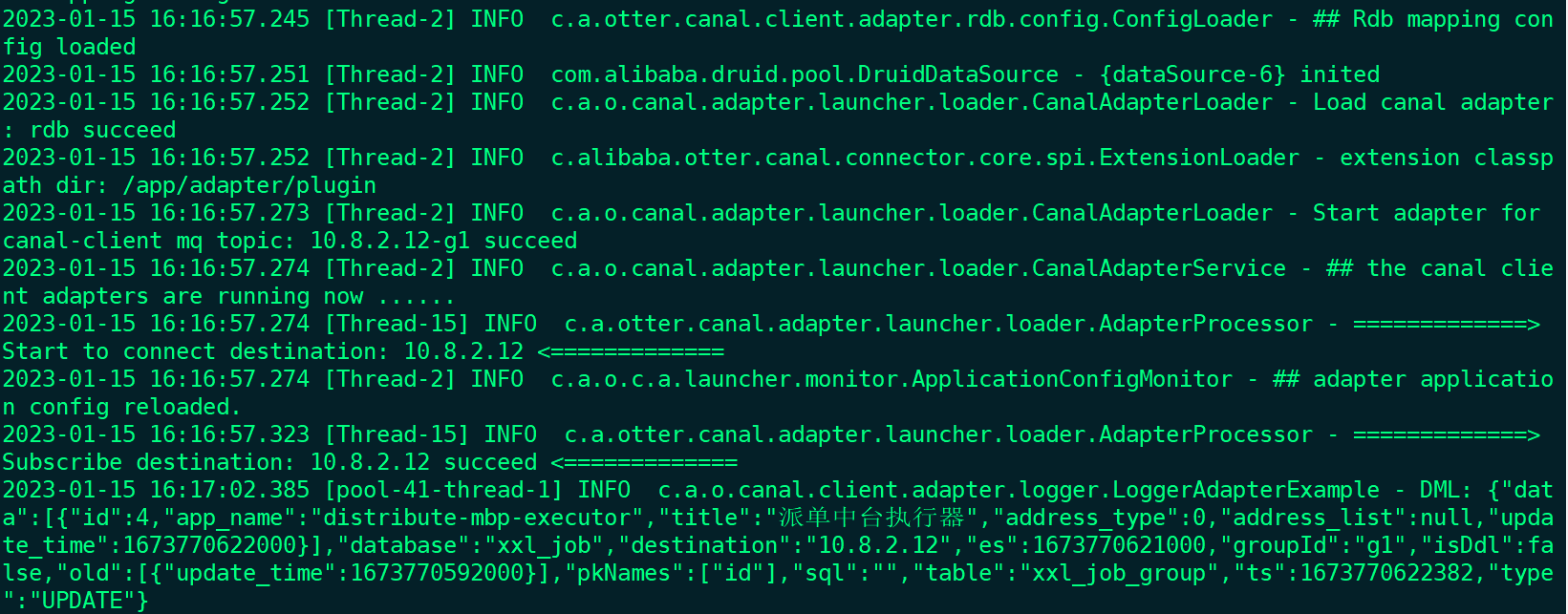
这样就好了。
在10.8.2.12的源数据库上插入数据:
insert into demotable666(UserName,UserLoginDate) values('john',DATE(NOW()));
在 10.8.2.17 可以看到新数据自动过来了,这样就搞定了。
六、拓展整库同步
上面我们实现了表同步,下面拓展说一下如何实现整库的同步:
1、设置application.yml,rdb增加一个key: mysqlbak2,jdbc.url 连接串不设置库名
canalAdapters:
- instance: 10.8.2.12 # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
- name: rdb
key: mysqlbak1
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://10.8.2.17:3306/xxl_job_bak?useUnicode=true
jdbc.username: sync_17
jdbc.password: xxxxxx
- name: rdb
key: mysqlbak2
properties:
jdbc.driverClassName: com.mysql.jdbc.Driver
jdbc.url: jdbc:mysql://10.8.2.17:3306/?useUnicode=true
jdbc.username: sync_17
jdbc.password: xxxxxx
2、编辑表同步配置文件mysqlbak2.yml
注意,里面其实只有一个配置起作用 database,而且目的库中必须事先建立好xxl_job的库表结构,库名也必须和源中库名完全一致,举例来说,从 xxl_job 只能同步到 xxl_job,不能从xxl_job同步到xxl_jobbak中。
#dataSourceKey: defaultDS
# cannal的instance或者MQ的topic
destination: 10.8.2.12
groupId: g1
outerAdapterKey: mysqlbak2
concurrent: true
dbMapping:
mirrorDb: true
database: xxl_job
然后我们看 10.8.2.17 上面 xxl_job 库里的数据就会增量开始跟源库同步了。