最近天天都在学习claude code,Skills == 工具箱(技能库)
我们可以把skills看成是一个个的小程序,这些程序有入口,有参数,有限制。
那通过一篇md文件,来引导claude来智能的传参调用你的程序,这样技能箱就越来越丰富。
一、我们首先准备这个可执行 python 脚本
这个是通过CLIProxyAPI的反代,把antigravity的gemini3模型给抽出来,然后生图
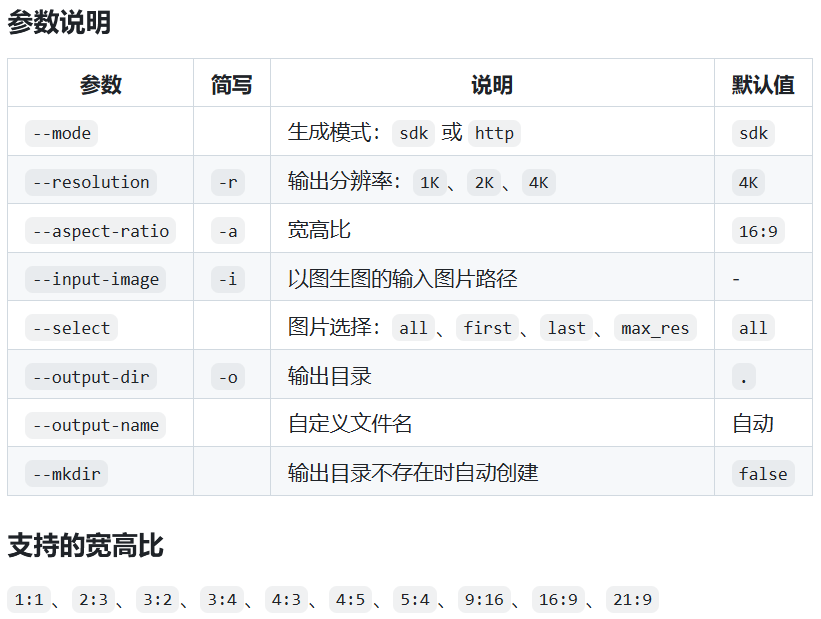
看最下面,有一堆参数
#!/usr/bin/env python3
# ============================================================
# Configuration - Edit these values before use
# 配置项 - 使用前请修改以下值
# ============================================================
API_BASE_URL = "http://127.0.0.1:8317" # API server address / API 服务器地址
API_KEY = "key" # Your API key / 你的 API 密钥
MODEL = "gemini-3-pro-image-preview" # Model name / 模型名称
# ============================================================
import argparse
import base64
import json
import os
import sys
from datetime import datetime
from pathlib import Path
from urllib import request
from mimetypes import guess_type
try:
from google import genai
from google.genai import types
except ImportError:
genai = None
types = None
VALID_ASPECT_RATIOS = ["1:1", "2:3", "3:2", "3:4", "4:3", "4:5", "5:4", "9:16", "16:9", "21:9"]
VALID_RESOLUTIONS = ["1K", "2K", "4K"]
def _resolve_output_dir(output_dir: str, mkdir: bool) -> str:
if os.path.isdir(output_dir):
return output_dir
if mkdir:
os.makedirs(output_dir, exist_ok=True)
return output_dir
print(f"Warning: Output directory not found: {output_dir}. Saving to current directory.")
return "."
def _build_filename(output_name: str | None, timestamp: str, index: int, default_ext: str) -> str:
if output_name:
root, ext = os.path.splitext(output_name)
if not ext:
ext = default_ext
suffix = f"_{index}" if index > 0 else ""
return f"{root}{suffix}{ext}"
return f"generated_{timestamp}_{index}{default_ext}"
def _load_image_inline(image_path: str) -> dict:
mime_type, _ = guess_type(image_path)
if mime_type is None:
mime_type = "image/png"
data = Path(image_path).read_bytes()
return {"inlineData": {"mimeType": mime_type, "data": base64.b64encode(data).decode("ascii")}}
def _post_json(url: str, body: dict) -> dict:
data = json.dumps(body).encode("utf-8")
req = request.Request(
url,
data=data,
headers={"Content-Type": "application/json", "x-goog-api-key": API_KEY},
)
resp = request.urlopen(req).read()
return json.loads(resp)
def _save_images(parts, output_dir: str, select: str, output_name: str | None, mkdir: bool) -> list[str]:
imgs = [p["inlineData"] for p in parts if "inlineData" in p]
if not imgs:
return []
if select == "first":
imgs = imgs[:1]
elif select == "last":
imgs = imgs[-1:]
elif select == "max_res":
imgs = imgs[-1:]
ts = datetime.now().strftime("%Y%m%d_%H%M%S")
output_dir = _resolve_output_dir(output_dir, mkdir)
saved = []
for i, img in enumerate(imgs):
data = base64.b64decode(img["data"])
ext = "jpg" if img.get("mimeType", "").endswith("jpeg") else "png"
filename = _build_filename(output_name, ts, i, f".{ext}")
path = Path(output_dir) / filename
path.write_bytes(data)
saved.append(str(path))
return saved
def _sdk_generate(prompt: str, output_dir: str, aspect_ratio: str, resolution: str, input_image: str | None,
output_name: str | None, mkdir: bool, select: str) -> list[str]:
if genai is None or types is None:
print("Error: google-genai is not installed.")
return []
client_kwargs = {"api_key": API_KEY}
if API_BASE_URL:
client_kwargs["http_options"] = {"base_url": API_BASE_URL}
client = genai.Client(**client_kwargs)
if input_image:
if not Path(input_image).exists():
print(f"Error: Input image not found: {input_image}")
return []
with open(input_image, "rb") as f:
image_bytes = f.read()
mime_type, _ = guess_type(input_image)
if mime_type is None:
mime_type = "image/png"
image_part = types.Part.from_bytes(data=image_bytes, mime_type=mime_type)
contents = [prompt, image_part]
else:
contents = prompt
try:
response = client.models.generate_content(
model=MODEL,
contents=contents,
config=types.GenerateContentConfig(
image_config=types.ImageConfig(
aspectRatio=aspect_ratio,
imageSize=resolution,
)
),
)
except Exception as exc:
print(f"API Error: {exc}")
return []
saved = []
ts = datetime.now().strftime("%Y%m%d_%H%M%S")
output_dir = _resolve_output_dir(output_dir, mkdir)
image_parts = []
for part in response.parts:
if part.text is not None:
print(f"Response text: {part.text}")
elif image := part.as_image():
image_parts.append(image)
if not image_parts:
return []
if select == "first":
image_parts = image_parts[:1]
elif select == "last":
image_parts = image_parts[-1:]
elif select == "max_res":
image_parts = [max(image_parts, key=lambda x: len(x.image_bytes))]
for i, image in enumerate(image_parts):
filename = _build_filename(output_name, ts, i, ".png")
path = Path(output_dir) / filename
image.save(path)
saved.append(str(path))
return saved
def _http_generate(prompt: str, output_dir: str, aspect_ratio: str, resolution: str, input_image: str | None,
select: str, output_name: str | None, mkdir: bool) -> list[str]:
if input_image and not Path(input_image).exists():
print(f"Error: Input image not found: {input_image}")
return []
url = f"{API_BASE_URL.rstrip('/')}/v1beta/models/{MODEL}:generateContent"
parts = [{"text": prompt}]
if input_image:
parts.append(_load_image_inline(input_image))
body = {
"contents": [{"parts": parts}],
"generationConfig": {
"responseModalities": ["TEXT", "IMAGE"],
"imageConfig": {"aspectRatio": aspect_ratio, "imageSize": resolution},
},
}
try:
resp = _post_json(url, body)
except Exception as exc:
print(f"API Error: {exc}")
return []
if "candidates" not in resp:
print(f"Unexpected response: {resp}")
return []
parts_out = resp["candidates"][0]["content"]["parts"]
return _save_images(parts_out, output_dir, select, output_name, mkdir)
def main():
parser = argparse.ArgumentParser(description="Generate images via SDK or HTTP")
parser.add_argument("prompt", nargs="*", help="Image description prompt")
parser.add_argument("--mode", default="sdk", choices=["sdk", "http"])
parser.add_argument("--aspect-ratio", "-a", default="16:9", choices=VALID_ASPECT_RATIOS)
parser.add_argument("--resolution", "-r", default="4K", choices=VALID_RESOLUTIONS)
parser.add_argument("--output-dir", "-o", default=".")
parser.add_argument("--output-name", default=None)
parser.add_argument("--mkdir", action="store_true")
parser.add_argument("--input-image", "-i", default=None)
parser.add_argument("--select", default="all", choices=["all", "first", "last", "max_res"])
args = parser.parse_args()
if not args.prompt:
parser.print_help()
sys.exit(1)
prompt = " ".join(args.prompt)
if args.mode == "sdk":
saved = _sdk_generate(
prompt=prompt,
output_dir=args.output_dir,
aspect_ratio=args.aspect_ratio,
resolution=args.resolution,
input_image=args.input_image,
output_name=args.output_name,
mkdir=args.mkdir,
select=args.select,
)
else:
saved = _http_generate(
prompt=prompt,
output_dir=args.output_dir,
aspect_ratio=args.aspect_ratio,
resolution=args.resolution,
input_image=args.input_image,
select=args.select,
output_name=args.output_name,
mkdir=args.mkdir,
)
if saved:
print(f"Generated {len(saved)} image(s):")
for f in saved:
print(f" - {Path(f).resolve()}")
else:
print("No images were generated.")
sys.exit(1)
if __name__ == "__main__":
main()
基本用法:
# Python 3.10+
# google-genai 包(SDK 模式需要)
# SDK 模式(默认)
python ~/.claude/skills/image-generator-hybrid/scripts/generate.py "山间日落" -r 4K -a 16:9
# HTTP 模式
python ~/.claude/skills/image-generator-hybrid/scripts/generate.py "山间日落" --mode http -r 4K
使用示例:
# 生成 4K 竖版图片
python ~/.claude/skills/image-generator-hybrid/scripts/generate.py "人像照片" -r 4K -a 9:16
# 以图生图
python ~/.claude/skills/image-generator-hybrid/scripts/generate.py "转换为赛博朋克风格" -i input.jpg
# 仅保存最高分辨率
python ~/.claude/skills/image-generator-hybrid/scripts/generate.py "风景" --select max_res
# 自定义输出位置
python ~/.claude/skills/image-generator-hybrid/scripts/generate.py "猫咪" -o ./images --mkdir --output-name cat
二、准备claude/skills目录结构
在 ~/.claude/新建skills/gen-image目录,在gen-image下建scripts目录,把python文件放进去
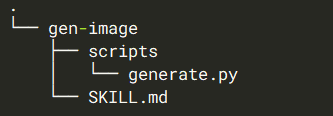
三、准备SKILL.md文件
---
name: gen-image
description: 同时支持 SDK 与 HTTP 两种方式生成图片,可按需切换保存策略。
allowed-tools: Bash(python:*)
---
# Image Generator (Hybrid) Skill
一个脚本同时支持 SDK 与 HTTP 直连两种模式。
## 配置
- **API 端点**: `http://127.0.0.1:8317/v1beta/models/gemini-3-pro-image-preview:generateContent`
- **模型**: `gemini-3-pro-image-preview`
- **API Key**: `key`
可通过环境变量覆盖默认配置:
- `IMAGE_API_KEY`: API 密钥
- `IMAGE_MODEL`: 使用的模型名称
- `IMAGE_API_BASE_URL`: API 基础地址
## 参数
- `--mode`: `sdk|http`(默认 `sdk`)
- `-r/--resolution`: `1K|2K|4K`
- `-a/--aspect-ratio`: `1:1|2:3|3:2|3:4|4:3|4:5|5:4|9:16|16:9|21:9`
- `-i/--input-image`: 以图生图输入图片路径
- `--select`: `all|first|last|max_res`
- `max_res` 会选择返回中“最大体积”的那张(通常是 4K)
- `-o/--output-dir`: 输出目录(默认当前目录)
- `--output-name`: 指定文件名(可选;若返回多张,自动追加 `_1/_2`)
- `--mkdir`: 当输出目录不存在时创建(默认 false);否则回退到当前目录
## 使用
```bash
# SDK 模式(默认)
python ~/.claude/skills/gen-image/scripts/generate.py "描述" -r 4K -a 16:9
# HTTP 模式(保存全部返回图片)
python ~/.claude/skills/gen-image/scripts/generate.py "描述" --mode http -r 4K -a 1:1 --select all
# 仅保存最大尺寸
python ~/.claude/skills/gen-image/scripts/generate.py "描述" --mode http -r 4K -a 1:1 --select max_res
```
看明白了吧,这个markdown 描述了这个技能的情况,配置、参数、使用
最厉害的是claude会根据这个markdown文件来自动调用这个脚本,自己匹配合适的参数,这才是最厉害的地方
那每个SKILL都是一个md文件,给个模板:
# 技能名称
简单说明这个技能是干嘛用的,一般在什么情况下会用到。
## 什么时候用
- 场景1:比如要上线新版本时
- 场景2:比如遇到某个特定错误时
## 具体步骤
1. 第一步要做什么(附上具体的命令)
2. 第二步...
3. 依次往下
## 怎么确认成功了
做完之后,通过哪些方法可以验证操作是成功的。
## 可能遇到的问题
- 问题1:如果遇到...,可以试试...
- 问题2:有时候会...,这时候应该...
四、配置Claude
在CLAUDE.md中添加
## 生图 生成图片
使用技能 ~/.claude/skills/gen-image
然后就可以在claude里面使用了
生图,4K,1:1,随机内容,仅保留最大分辨率,输出在当前目录,文件名:001.png
五、发散思维
这个是用的gemini的模型,那改改程序,用前面文章提供的接口:
就可以随便生图了