Cluade code、Codex、Gemini三架马车是齐头并进的势头,那将来必定是Farm农场和Token战争的年代。
那我们必须准备好,自己在局域网部署大模型,不依赖于任何的提供厂家。
本篇就是从光杆的debian 12开始,搭配AMD 6700 xt 12G的显卡,从头搭建一个大模型服务器,供局域网的同事们使用
一、Debian安装
光杆debian iso下载
https://gemmei.ftp.acc.umu.se/cdimage/archive/12.0.0/amd64/iso-cd/debian-12.0.0-amd64-netinst.iso
用rufus刻录到U盘,然后安装
root用户,然后建立一个普通用户debian
二、Debian准备驱动
# root 用户
apt update && sudo apt upgrade -y
apt install sudo
# debian用户
sudo apt install -y wget gnupg2 curl software-properties-common linux-headers-$(uname -r)
wget -qO - https://repo.radeon.com/rocm/rocm.gpg.key | sudo gpg --dearmor -o /etc/apt/keyrings/rocm.gpg
echo "deb [arch=amd64 signed-by=/etc/apt/keyrings/rocm.gpg] https://repo.radeon.com/amdgpu/6.0/ubuntu jammy main" | sudo tee /etc/apt/sources.list.d/amdgpu.list
echo "deb [arch=amd64 signed-by=/etc/apt/keyrings/rocm.gpg] https://repo.radeon.com/rocm/apt/6.0 jammy main" | sudo tee /etc/apt/sources.list.d/rocm.list
sudo apt update
sudo apt install -y amdgpu-dkms rocm-hip-libraries
sudo tee /etc/apt/preferences.d/rocm-pin-600 <<EOF
Package: *
Pin: origin repo.radeon.com
Pin-Priority: 600
EOF
sudo apt update
sudo apt install -y amdgpu-dkms rocm-hip-libraries
sudo usermod -aG video,render $USER
sudo reboot
然后就安装好了显卡驱动,解释一下,必须让新repo的优先级提高,才能安装!确认一下:
rocminfo | grep gfx

看到gfx103x的代码,就OK了
三、安装ollama
# debian 用户
sudo curl -fsSL https://ollama.com/install.sh | sh
然后修改service文件
# vi /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
Environment="PATH=/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games"
# 核心修复:强制将 gfx1031 伪装成 gfx1030
Environment="HSA_OVERRIDE_GFX_VERSION=10.3.0"
# 可选:如果你要让局域网其他人访问
Environment="OLLAMA_HOST=0.0.0.0"
[Install]
WantedBy=default.target
重启
systemctl daemon-reload
systemctl ollama restart
看看版本,拉取模型
ollama -v
ollama version is 0.15.4
# 拉取模型
ollama pull qwen2.5:14b
# 看看都有什么模型
curl -s http://127.0.0.1:11434/v1/models
Ollama从(v0.14.0+)开始,提供了Anthropic’s Messages API,也就是说直接可以用Claude code来访问了。
四、测试一下
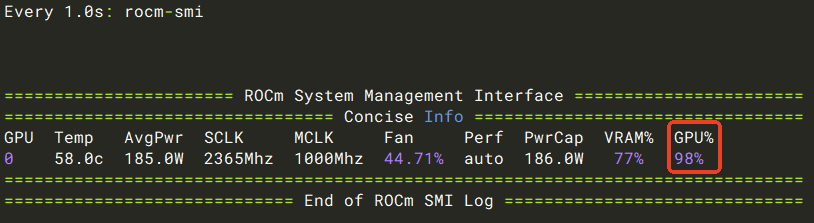
先开个独立ssh窗口,观察GPU
watch -n 1 rocm-smi
然后测试
ollama run qwen2.5:14b "写一个快速排序算法" --verbose
看到GPU很高
给出答案:
当然,下面是一个使用Python编写的快速排序(Quick Sort)算法的示例。快速排序是一种非常高效的排序算法,它基于分治法的原则来工作。
### 快速排序的基本思想:
- 选择一个基准值(pivot),将数组中的元素根据与该基准值的大小关系分成两部分。
- 小于基准值的部分放在左边,大于基准值的部分放在右边。
- 对这两部分递归地进行同样的操作,直到每个子数组只有一个元素或为空。
### Python代码实现:
```python
def quick_sort(arr):
if len(arr) <= 1:
return arr
# 选择基准值 pivot
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot] # 小于基准值的元素集合
middle = [x for x in arr if x == pivot] # 等于基准值的元素集合
right = [x for x in arr if x > pivot] # 大于基准值的元素集合
return quick_sort(left) + middle + quick_sort(right)
# 示例使用
arr = [3, 6, 8, 10, 1, 2, 1]
sorted_arr = quick_sort(arr)
print("排序后的数组:", sorted_arr)
```
### 解释代码:
- 函数 `quick_sort` 接收一个列表(或数组)作为参数。
- 如果输入的长度小于等于1,直接返回该输入,因为单个元素或者空集已经是有序的。
- 选择中间位置的元素作为基准值 pivot。这里可以改进为随机选取以优化性能和稳定性。
- 构建三个列表:`left` 包含所有比 pivot 小的元素;`middle` 包含等于 pivot 的所有元素; `right` 包含所有大于 pivot 的元素。
- 递归地对 left 和 right 列表进行快速排序,然后将结果合并。
### 性能和改进:
- 快速排序在平均情况下的时间复杂度为 O(n log n),但在最坏的情况下(例如输入已经完全有序),它的性能会降级到 O(n^2)。
- 为了减少发生最差情况的概率,可以选择随机元素作为基准值或者使用三数取中法选择更合适的基准值。
以上就是一个快速排序算法的完整实现。希望这对你有所帮助!如果你有任何问题或需要进一步解释,请告诉我。
total duration: 26.640771498s
load duration: 9.655767337s
prompt eval count: 34 token(s)
prompt eval duration: 124.326028ms
prompt eval rate: 273.47 tokens/s
eval count: 528 token(s)
eval duration: 16.361471625s
eval rate: 32.27 tokens/s
五、结合Claude code
claude code的安装就不说了
export ANTHROPIC_API_KEY=""
export ANTHROPIC_BASE_URL="http://192.168.0.10:11434"
claude --model qwen2.5:14b
然后就可以问一些问题和指导代码了,但是确认弱得可怜。
只能片面实现一些功能,对于空手套狼,徒手建一个新项目还做不到!!
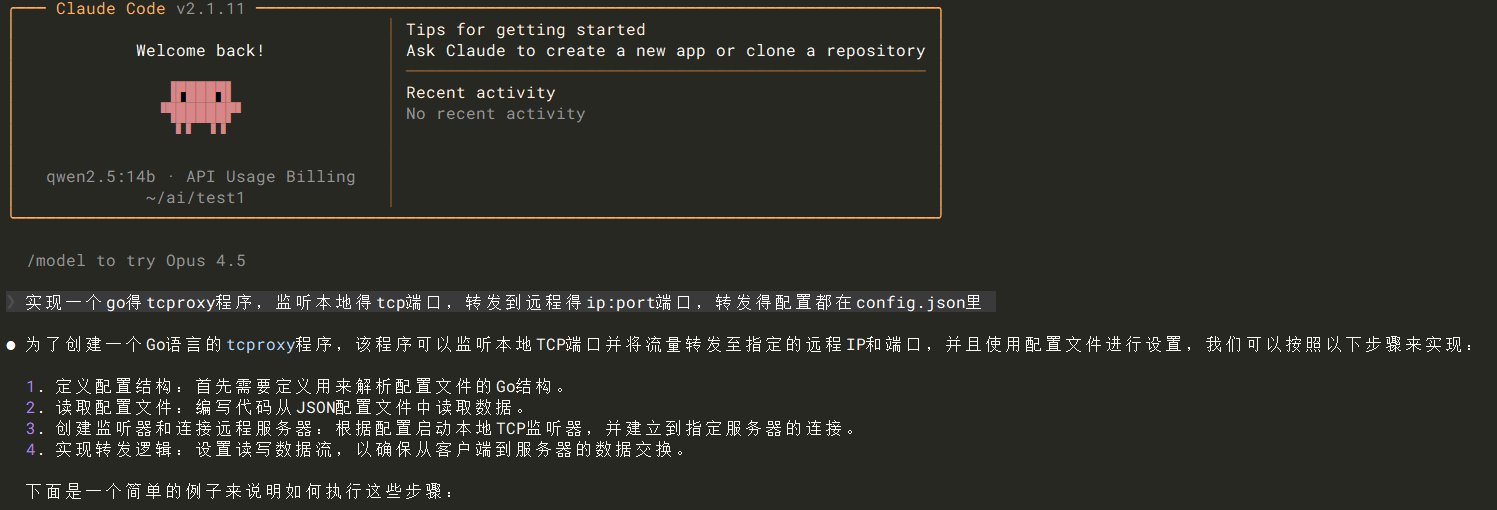
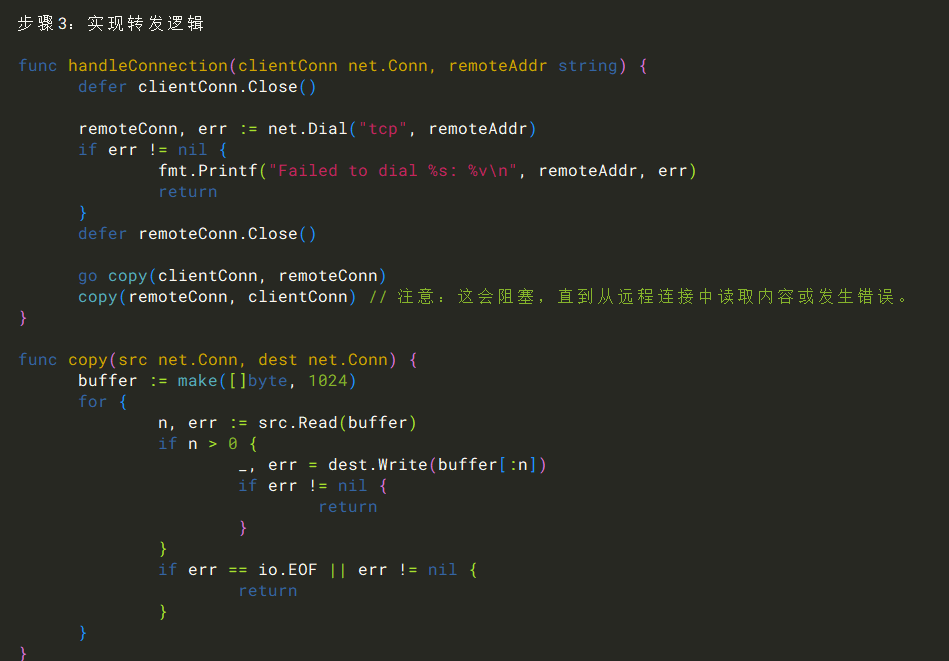
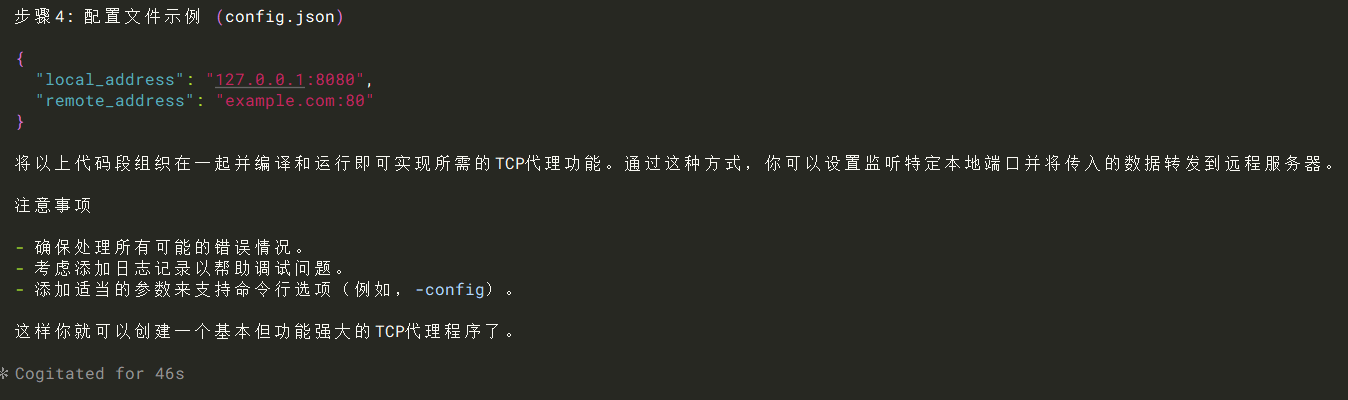
可以参考一下。