谷歌推出了Gemma4,那有好事者船载以入,直接破了它的道德感,可以逆向,破解,我们来试试吧
运行环境:
Ubuntu 22.04,Nvidia 3060 8G显卡
# 首先下载模型
uv pip install -U "huggingface_hub"
uv tool run hf auth login --token hf_xxxxxxxx
# 破限模型的地址:https://huggingface.co/HauhauCS/Gemma-4-E4B-Uncensored-HauhauCS-Aggressive
# 本来应该运行Q5_K_M 或者Q5_K_P,但是还要跑多模态,降一档
# 跑Q4_K_P 或者Q4_K_M加上多模态文件
# 下载Q4_KM
uv tool run hf download HauhauCS/Gemma-4-E4B-Uncensored-HauhauCS-Aggressive Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf
/home/ubuntu/.cache/huggingface/hub/models--HauhauCS--Gemma-4-E4B-Uncensored-HauhauCS-Aggressive/snapshots/45b6a334b4bcd1d7f37179df58b3b1d66a184e5d/Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf
# 下载多模态文件
uv tool run hf download HauhauCS/Gemma-4-E4B-Uncensored-HauhauCS-Aggressive mmproj-Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-f16.gguf
/home/ubuntu/.cache/huggingface/hub/models--HauhauCS--Gemma-4-E4B-Uncensored-HauhauCS-Aggressive/snapshots/45b6a334b4bcd1d7f37179df58b3b1d66a184e5d/mmproj-Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-f16.gguf
然后需要编译llama.app,否则认不出gemma4这个最新的模型:
apt install nvidia-driver-590
apt install nvidia-cuda-toolkit
apt install gcc-10 g++-10
git clone https://github.com/ggerganov/llama.cpp
cd llama.app
# apt 安装的590其实版本比较旧,但是ubuntu 22.04自带的gcc11版本高了,导致cuda的编译认不出来高版本的文件
# 所以必须用低版本的gcc来编译旧版本的cuda驱动
cmake -S . -B build -DCMAKE_BUILD_TYPE=Release \
-DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES=86 \
-DCMAKE_CUDA_HOST_COMPILER=/usr/bin/gcc-10
cmake --build build --config Release -j 8
cd build/bin
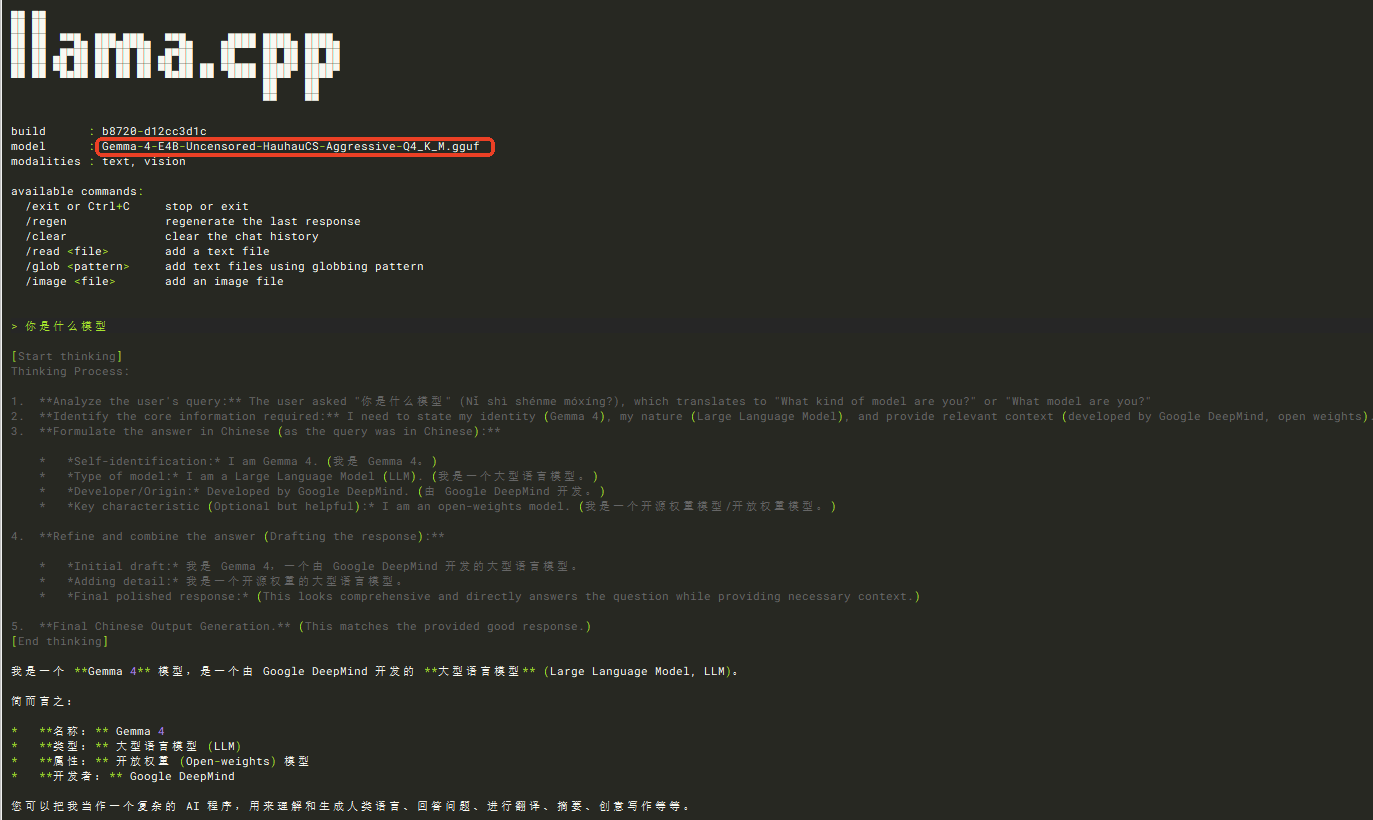
编译好后运行测试一下:
./llama-cli -m /home/ubuntu/.cache/huggingface/hub/models--HauhauCS--Gemma-4-E4B-Uncensored-HauhauCS-Aggressive/snapshots/45b6a334b4bcd1d7f37179df58b3b1d66a184e5d/Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf \
--mmproj /home/ubuntu/.cache/huggingface/hub/models--HauhauCS--Gemma-4-E4B-Uncensored-HauhauCS-Aggressive/snapshots/45b6a334b4bcd1d7f37179df58b3b1d66a184e5d/mmproj-Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-f16.gguf \
-p "你是一个有用的人工智能助手,尽量回答问题。" \
-cnv -ngl 42 --temp 1.0 --top-p 0.95 --top-k 99 --jinja
参数解释:
这串参数可以说是控制大模型“性格”和“性能”的控制台。给你一份炼丹师必备的参数备忘录:
-cnv(Conversation Mode): 开启连续对话模式。 加上它,程序就不再是“回答完你的一句话就直接退出”,而是会变成像 ChatGPT 那样的聊天窗口,你可以一直和它连续对话,并且它能记住你们的上下文。-ngl 42(Number of GPU Layers): 显卡加速层数。 这个参数极其关键!它决定了你要把模型的多少层神经网络“卸载”到显存里去跑。填42通常是一个足够大的数字(很多 7B/8B 级别的模型也就 32 层左右),这意味着它会把整个模型的计算任务全部塞进你的显卡里,彻底榨干硬件算力,实现推理速度的最大化。--temp 1.0(Temperature): 温度值 / 创造力。 控制 AI 回答的随机性和发散程度。1.0是默认偏活跃的设定,适合日常聊天或创意写作。- 如果你让它写代码或翻译严谨的文档,建议调低到
0.1 - 0.3(极其老实,绝不胡编)。 - 如果调到
1.5以上,它就开始天马行空甚至胡言乱语了。
--top-p 0.95(Nucleus Sampling): 核心采样 / 靠谱过滤。 AI 在预测下一个词时,脑子里会有成千上万个候选项。0.95意味着程序会把那些概率极低、看起来像“胡言乱语”的尾巴词汇直接砍掉,只在累计概率达到 95% 的“靠谱候选池”里做随机选择。--top-k 64(Top-K Sampling): 候选词截断。 这是top-p的双保险。它强制 AI 在生成下一个词时,无论概率如何分布,永远只看排名前 64 位的最有可能的词。这能极大地防止模型在长篇大论时突然“精神错乱”。--jinja: 原生模板解析引擎。 这是针对现代模型(如 Gemma、Llama-3 等)的“外挂”。新一代大模型在对话时需要非常严格的隐藏控制符(比如<start_of_turn>user等)。加上--jinja,llama.cpp 就会自动从 GGUF 文件内部读取作者写好的官方模板并完美应用,彻底免去了你手动拼装格式的痛苦,防止模型因为格式不对而产生幻觉。
最后,做成服务,提供一个web界面
./llama-server -m /home/ubuntu/.cache/huggingface/hub/models--HauhauCS--Gemma-4-E4B-Uncensored-HauhauCS-Aggressive/snapshots/45b6a334b4bcd1d7f37179df58b3b1d66a184e5d/Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-Q4_K_M.gguf \
--mmproj /home/ubuntu/.cache/huggingface/hub/models--HauhauCS--Gemma-4-E4B-Uncensored-HauhauCS-Aggressive/snapshots/45b6a334b4bcd1d7f37179df58b3b1d66a184e5d/mmproj-Gemma-4-E4B-Uncensored-HauhauCS-Aggressive-f16.gguf \
-ngl 42 --temp 1.0 --top-p 0.95 --top-k 99 --jinja \
--host 0.0.0.0 --port 12345
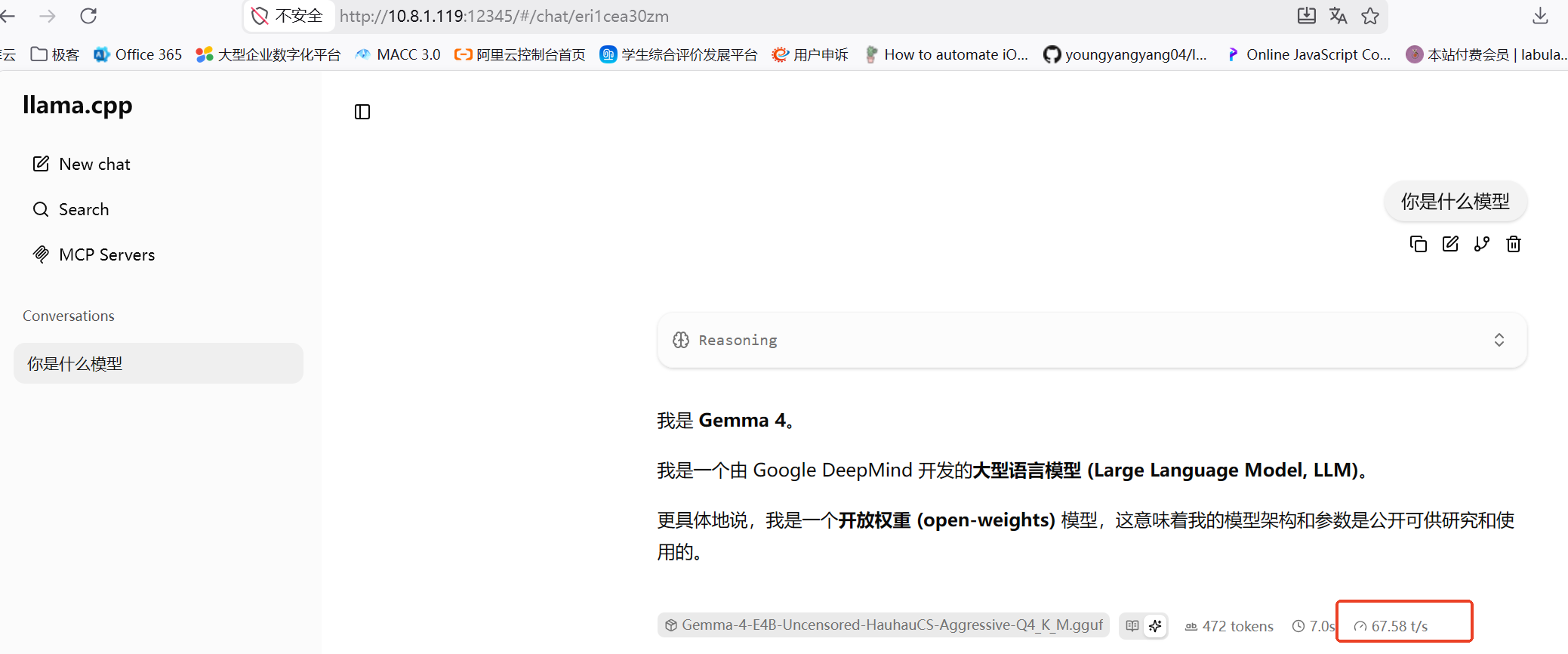
打完收工,提供给本地的openclaw大龙虾用。