Claude Opus蒸馏Qwen3.5,9B小模型工具调用满分。9B的蒸馏模型,工具调用测试居然打了满分。
不知道为什么,huggingface.co 总给我推Jackrong的模型
从刚开始用opus数据蒸馏Qwen3.5开始,到现在的居然命名为 Qwopus3.5-9B-V3-GGUF
后面的9B是比较适合 Nvidia 3060 8G显卡的实现
我们来看看
apt-get update
apt-get install pciutils build-essential cmake curl libcurl4-openssl-dev -y
apt-get search nvidia-driver
#还是590是最新的
apt install nvidia-driver-590 nvidia-cuda-toolkit libssl-dev
git clone https://github.com/ggml-org/llama.cpp
# 指定静态编译
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON
# 编译出主要得可运行程序
cd llama.app
cmake --build build --config Release -j 8
# 装UV
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
# 建目录
mkdir qwen
cd qwen
uv venv --python 3.12
source .venv/bin/activate
uv pip install huggingface_hub hf_transfer
hf auth login --token hf_xxxxx
# 下载Q4_K_M的量化文件
hf download Jackrong/Qwopus3.5-9B-v3-GGUF --local-dir Jackrong/Qwopus3.5-9B-v3-GGUF Qwopus3.5-9B-v3.Q4_K_M.gguf
# 下载多模态量化文件
hf download Jackrong/Qwopus3.5-9B-v3-GGUF --local-dir Jackrong/Qwopus3.5-9B-v3-GGUF mmproj.gguf
编写个run.sh
#!/bin/bash
#
~/llama.cpp/build/bin/llama-server \
--model ~/qwen/Jackrong/Qwopus3.5-9B-v3-GGUF/Qwopus3.5-9B-v3.Q4_K_M.gguf \
--mmproj ~/qwen/Jackrong/Qwopus3.5-9B-v3-GGUF/mmproj.gguf \
--temp 1.0 \
--top-p 0.95 \
--top-k 64 \
--alias "Jackrong/Qwopus3.5-9B-v3-GGUF" \
--host 0.0.0.0 --port 8001 \
--chat-template-kwargs '{"enable_thinking":true}'
打开 http://127.0.0.1:8001
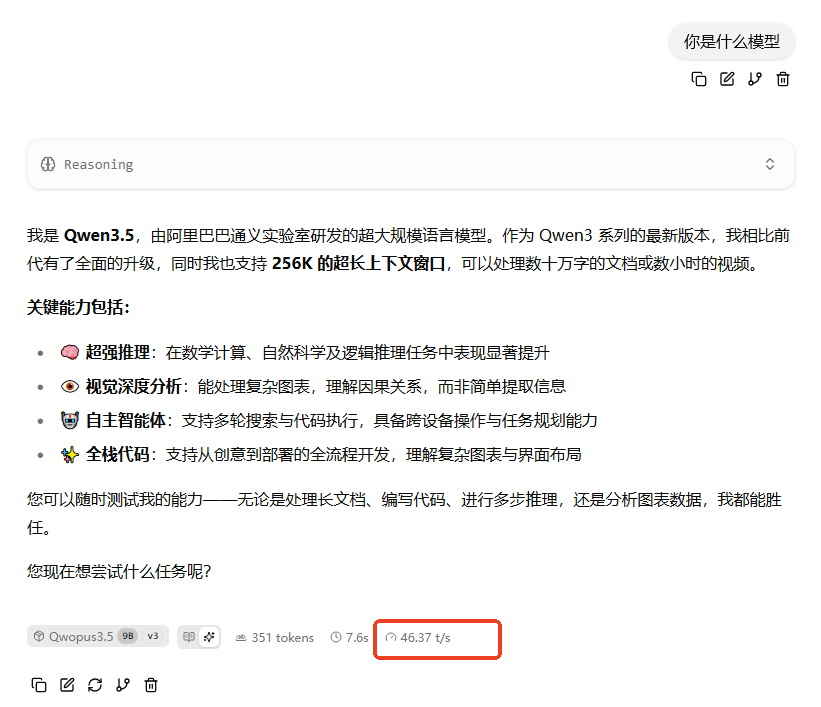
还可以,试试看给龙虾用
Jackrong 也着重提到了 unsloth,看来炼丹还是比较好玩啊。